API Calculation with Xarray + Dask#
Scott Wales, CLEX CMS
Let’s look at how we can calculate the antecedent precipitation index (API) on a large dataset with Xarray and Dask.
API is defined from precipitation in a recursive way:
API(t0) = precip(t0)
API(t) = k * API(t - 1) + precip(t)
with k < 1, so that precipitation on previous days impacts the API but that impact decays over time.
To start out with, let’s import some libraries and set up a Dask cluster - I’m running this notebook on https://ood.nci.org.au
import xarray
import numpy
import dask.array
import matplotlib.pyplot as plt
xarray.set_options(display_expand_data=False);
import climtas.nci
climtas.nci.Client()
Client
Client-138a2be4-4d9a-11ec-bc04-fa163e54927d
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /node/ood-vn6/26243/proxy/8787/status |
Cluster Info
LocalCluster
2ca2f1f4
| Dashboard: /node/ood-vn6/26243/proxy/8787/status | Workers: 4 |
| Total threads: 4 | Total memory: 11.23 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-6dc9cf31-2835-4499-9198-67d1dea14566
| Comm: tcp://127.0.0.1:37215 | Workers: 4 |
| Dashboard: /node/ood-vn6/26243/proxy/8787/status | Total threads: 4 |
| Started: Just now | Total memory: 11.23 GiB |
Workers
Worker: 0
| Comm: tcp://10.0.128.134:44215 | Total threads: 1 |
| Dashboard: /node/ood-vn6/26243/proxy/37089/status | Memory: 2.81 GiB |
| Nanny: tcp://127.0.0.1:44571 | |
| Local directory: /local/w35/saw562/tmp/dask-worker-space/worker-tlpd51xc | |
Worker: 1
| Comm: tcp://10.0.128.134:39293 | Total threads: 1 |
| Dashboard: /node/ood-vn6/26243/proxy/45357/status | Memory: 2.81 GiB |
| Nanny: tcp://127.0.0.1:42113 | |
| Local directory: /local/w35/saw562/tmp/dask-worker-space/worker-bsooahpt | |
Worker: 2
| Comm: tcp://10.0.128.134:37385 | Total threads: 1 |
| Dashboard: /node/ood-vn6/26243/proxy/38909/status | Memory: 2.81 GiB |
| Nanny: tcp://127.0.0.1:44871 | |
| Local directory: /local/w35/saw562/tmp/dask-worker-space/worker-hwk_syl7 | |
Worker: 3
| Comm: tcp://10.0.128.134:39297 | Total threads: 1 |
| Dashboard: /node/ood-vn6/26243/proxy/40713/status | Memory: 2.81 GiB |
| Nanny: tcp://127.0.0.1:33853 | |
| Local directory: /local/w35/saw562/tmp/dask-worker-space/worker-p3qi1ruc | |
For our sample dataset, I’ll use FROGs, which provides precip from a number of datasets regridded to a common one degree grid. The data is chunked by default with one chunk per year in the time axis, since that’s how the files themselves are split up.
ds = xarray.open_mfdataset('/g/data/ua8/Precipitation/FROGs/1DD_V1/ERA5/*.nc')
precip = ds.rain
precip
<xarray.DataArray 'rain' (time: 15341, lat: 180, lon: 360)>
dask.array<chunksize=(365, 180, 360), meta=np.ndarray>
Coordinates:
* time (time) datetime64[ns] 1979-01-01T13:30:00 ... 2020-12-31
* lon (lon) float64 -179.5 -178.5 -177.5 -176.5 ... 177.5 178.5 179.5
* lat (lat) float64 -89.5 -88.5 -87.5 -86.5 -85.5 ... 86.5 87.5 88.5 89.5
Attributes:
standard_name: lwe_precipitation_rate
long_name: Total precipitation, ERA5 reanalysis daily accumulated ra...
units: mm/day
comment: This daily precipitation is prepared by creating a accumu...- time: 15341
- lat: 180
- lon: 360
- dask.array<chunksize=(365, 180, 360), meta=np.ndarray>
Array Chunk Bytes 3.70 GiB 90.47 MiB Shape (15341, 180, 360) (366, 180, 360) Count 126 Tasks 42 Chunks Type float32 numpy.ndarray - time(time)datetime64[ns]1979-01-01T13:30:00 ... 2020-12-31
- standard_name :
- time
- long_name :
- time
- axis :
- T
- comment :
- The time values of the grid, following the standard CF calendar, in days, centred, since 1970-01-01 00:00:00
array(['1979-01-01T13:30:00.000000000', '1979-01-02T12:00:00.000000000', '1979-01-03T12:00:00.000000000', ..., '2020-12-29T00:00:00.000000000', '2020-12-30T00:00:00.000000000', '2020-12-31T00:00:00.000000000'], dtype='datetime64[ns]') - lon(lon)float64-179.5 -178.5 ... 178.5 179.5
- standard_name :
- longitude
- long_name :
- longitude
- units :
- degrees_east
- axis :
- X
- comment :
- The longitude values of the grid, in degrees, ranging between [-179.5; 179.5]. The grid is centred, i.e., a value of +0.5 corresponds to the degree [0W, 1W]
array([-179.5, -178.5, -177.5, ..., 177.5, 178.5, 179.5])
- lat(lat)float64-89.5 -88.5 -87.5 ... 88.5 89.5
- standard_name :
- latitude
- long_name :
- latitude
- units :
- degrees_north
- axis :
- Y
- comment :
- The latitude values of the grid, in degrees, ranging between [-89.5; 89.5]. The grid is centred, i.e., a value of +0.5 corresponds to the degree [0N, 1N]
array([-89.5, -88.5, -87.5, -86.5, -85.5, -84.5, -83.5, -82.5, -81.5, -80.5, -79.5, -78.5, -77.5, -76.5, -75.5, -74.5, -73.5, -72.5, -71.5, -70.5, -69.5, -68.5, -67.5, -66.5, -65.5, -64.5, -63.5, -62.5, -61.5, -60.5, -59.5, -58.5, -57.5, -56.5, -55.5, -54.5, -53.5, -52.5, -51.5, -50.5, -49.5, -48.5, -47.5, -46.5, -45.5, -44.5, -43.5, -42.5, -41.5, -40.5, -39.5, -38.5, -37.5, -36.5, -35.5, -34.5, -33.5, -32.5, -31.5, -30.5, -29.5, -28.5, -27.5, -26.5, -25.5, -24.5, -23.5, -22.5, -21.5, -20.5, -19.5, -18.5, -17.5, -16.5, -15.5, -14.5, -13.5, -12.5, -11.5, -10.5, -9.5, -8.5, -7.5, -6.5, -5.5, -4.5, -3.5, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 10.5, 11.5, 12.5, 13.5, 14.5, 15.5, 16.5, 17.5, 18.5, 19.5, 20.5, 21.5, 22.5, 23.5, 24.5, 25.5, 26.5, 27.5, 28.5, 29.5, 30.5, 31.5, 32.5, 33.5, 34.5, 35.5, 36.5, 37.5, 38.5, 39.5, 40.5, 41.5, 42.5, 43.5, 44.5, 45.5, 46.5, 47.5, 48.5, 49.5, 50.5, 51.5, 52.5, 53.5, 54.5, 55.5, 56.5, 57.5, 58.5, 59.5, 60.5, 61.5, 62.5, 63.5, 64.5, 65.5, 66.5, 67.5, 68.5, 69.5, 70.5, 71.5, 72.5, 73.5, 74.5, 75.5, 76.5, 77.5, 78.5, 79.5, 80.5, 81.5, 82.5, 83.5, 84.5, 85.5, 86.5, 87.5, 88.5, 89.5])
- standard_name :
- lwe_precipitation_rate
- long_name :
- Total precipitation, ERA5 reanalysis daily accumulated rainfall from 0h to 0h
- units :
- mm/day
- comment :
- This daily precipitation is prepared by creating a accumulation over 24h from the source 18hr precipitation, regridded from 0.25 x 0.25 degree to 1 x 1 degree with Python library xESMF. Units have been converted from m to mm/day (data*1000).
Calculation on a single point#
To start out with, let’s make sure we can do the calculation on a single grid point.
Start out by saving the grid point’s precip time series in a variable
precip_mel = precip.sel(lat=-37.81, lon=144.96, method='nearest').load()
Why the .load()?
I’ve done a .load() here because we’ll be looping over time. Without the .load() Dask will try to read from the file at every loop iteration, with it it will only read from the file once - though this does come at the cost of more memory usage so we need to be carefull of how large the grid is that we’re loading.
Now we can do the calculation. numpy.zeros_like() will create an empty array that’s the same shape as the input array, which we’ll use to store the API values. Then we can just implement the algorithm with a loop
# Empty array to store the output
api_mel = numpy.zeros_like(precip_mel)
k = 0.95
# Initial value is precip(t0)
api_mel[0] = precip_mel[0]
# Following values are k * api(t - 1) + precip(t)
for i in range(1, len(precip_mel)):
api_mel[i] = k * api_mel[i - 1] + precip_mel[i]
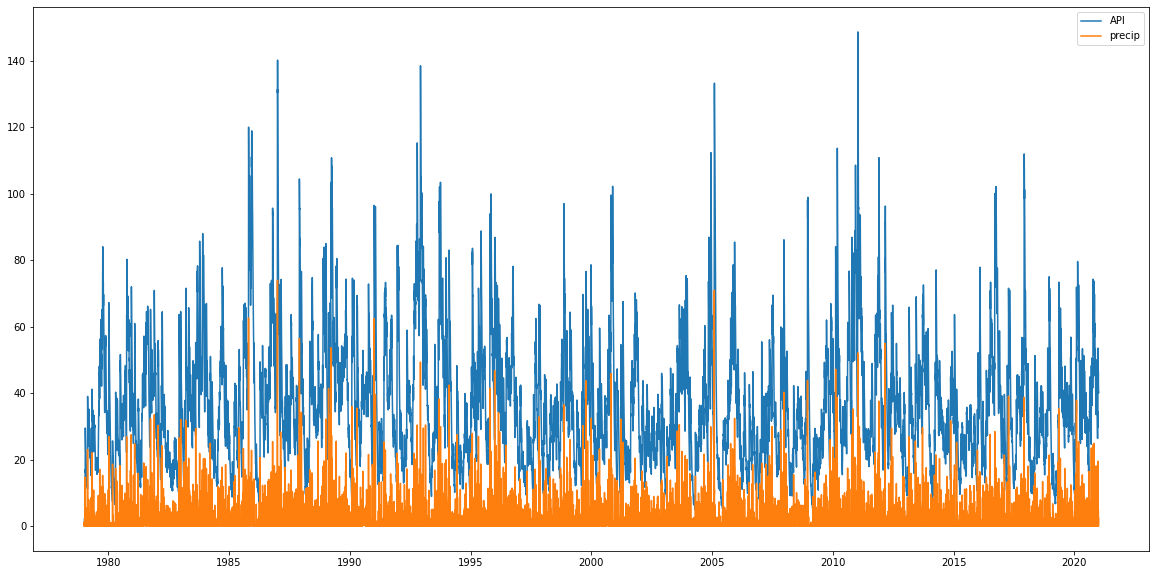
Plotting the values they look ok, API is higher than the original precip values because of the accumulation but has the same sort of peak structure showing the decay is working as well.
plt.figure(figsize=(20,10))
plt.plot(precip_mel.time, api_mel, label='API')
plt.plot(precip_mel.time, precip_mel, label='precip')
plt.legend();
Calculation over the whole grid#
With the caluclation working on a single grid point, let’s look at expanding it to the whole grid. It’s generally much more efficient to work on the whole grid at once, rather than single grid points one at a time, because of the way data gets laid out in the file.
The calculation looks much like the single grid point calculation, we’ve just added the extra dimensions when indexing the arrays
precip_year = precip.sel(time='1980').load()
api_year = numpy.zeros_like(precip_year)
api_year[0,:,:] = precip_year[0,:,:]
for i in range(1, precip_year.sizes['time']):
api_year[i,:,:] = k * api_year[i - 1,:,:] + precip_year[i,:,:]
A quick plot of the final time looks reasonable
plt.figure(figsize=(20,10))
plt.pcolormesh(api_year[-1, :, :], cmap='Blues');

We’ve calculated a year of data, so let’s save it to a netcdf file. First convert the numpy array to an xarray object - we can grab the coordinates from the original precip data, then save to file with xarray.DataArray.to_netcdf()
api_year = xarray.DataArray(api_year, name='api', coords=precip_year.coords)
api_year.to_netcdf('/local/w35/saw562/tmp/frogs_era5_api_1980.nc')
Convert to a function#
With a single year working we should make a function to consolidate where we’ve got to so far and to make sure we can easily change the year, without needing to do lots of copying and pasting.
This won’t be the final function, for now this will only work properly for 1980, but it’s important to be methodical and make sure what we’ve already done is still working.
def api_at_year(precip, year):
"""
Returns the API measure for a given year
"""
precip_year = precip.sel(time=year).load()
api_year = numpy.zeros_like(precip_year)
api_year[0,:,:] = precip_year[0,:,:]
for i in range(1, precip_year.sizes['time']):
api_year[i,:,:] = k * api_year[i - 1,:,:] + precip_year[i,:,:]
api_year = xarray.DataArray(api_year, name='api', coords=precip_year.coords)
return api_year
%%time
api_at_year(precip, '1980')
CPU times: user 1.27 s, sys: 262 ms, total: 1.53 s
Wall time: 2.34 s
<xarray.DataArray 'api' (time: 366, lat: 180, lon: 360)> 0.01768 0.01768 0.01768 0.01768 0.01632 ... 4.527 4.523 4.533 4.528 4.527 Coordinates: * time (time) datetime64[ns] 1980-01-01T12:00:00 ... 1980-12-31T12:00:00 * lon (lon) float64 -179.5 -178.5 -177.5 -176.5 ... 177.5 178.5 179.5 * lat (lat) float64 -89.5 -88.5 -87.5 -86.5 -85.5 ... 86.5 87.5 88.5 89.5
- time: 366
- lat: 180
- lon: 360
- 0.01768 0.01768 0.01768 0.01768 0.01632 ... 4.523 4.533 4.528 4.527
array([[[0.01767761, 0.01767761, 0.01767761, ..., 0.01767761, 0.01767761, 0.01767761], [0.16861725, 0.16589761, 0.15773872, ..., 0.18901448, 0.17949577, 0.17133687], [0.41746366, 0.4161038 , 0.4229029 , ..., 0.42018327, 0.41746366, 0.4120244 ], ..., [0.04215431, 0.04487394, 0.04351413, ..., 0.04759357, 0.04487394, 0.04215431], [0.04487394, 0.04487394, 0.04487394, ..., 0.05439266, 0.05167302, 0.05031321], [0.066631 , 0.066631 , 0.066631 , ..., 0.07207027, 0.07207027, 0.06935064]], [[0.05894805, 0.05894805, 0.05894805, ..., 0.06030786, 0.06030786, 0.06030786], [0.32200456, 0.31942087, 0.31166995, ..., 0.3468212 , 0.3391382 , 0.32730782], [0.8602879 , 0.88075304, 0.9089693 , ..., 0.8723902 , 0.8602879 , 0.8388028 ], ... [5.651482 , 5.66441 , 5.668544 , ..., 5.4923625 , 5.56027 , 5.611495 ], [5.052609 , 5.0709877 , 5.069583 , ..., 5.049734 , 5.0416374 , 5.0543537 ], [4.745502 , 4.7552304 , 4.751371 , ..., 4.7600756 , 4.7546854 , 4.756812 ]], [[3.2373145 , 3.245625 , 3.248426 , ..., 3.2445123 , 3.2476687 , 3.255358 ], [2.1031456 , 2.164625 , 2.20095 , ..., 1.9554576 , 1.9711627 , 2.0395157 ], [1.5107511 , 1.6148776 , 1.7048018 , ..., 1.2923038 , 1.3440533 , 1.4011242 ], ..., [5.385226 , 5.397507 , 5.395995 , ..., 5.2367816 , 5.298574 , 5.347238 ], [4.824455 , 4.8419147 , 4.837861 , ..., 4.824444 , 4.815392 , 4.8261123 ], [4.5163856 , 4.5256276 , 4.521961 , ..., 4.5329504 , 4.5278296 , 4.52713 ]]], dtype=float32) - time(time)datetime64[ns]1980-01-01T12:00:00 ... 1980-12-...
- standard_name :
- time
- long_name :
- time
- axis :
- T
- comment :
- The time values of the grid, following the standard CF calendar, in days, centred, since 1970-01-01 00:00:00
array(['1980-01-01T12:00:00.000000000', '1980-01-02T12:00:00.000000000', '1980-01-03T12:00:00.000000000', ..., '1980-12-29T12:00:00.000000000', '1980-12-30T12:00:00.000000000', '1980-12-31T12:00:00.000000000'], dtype='datetime64[ns]') - lon(lon)float64-179.5 -178.5 ... 178.5 179.5
- standard_name :
- longitude
- long_name :
- longitude
- units :
- degrees_east
- axis :
- X
- comment :
- The longitude values of the grid, in degrees, ranging between [-179.5; 179.5]. The grid is centred, i.e., a value of +0.5 corresponds to the degree [0W, 1W]
array([-179.5, -178.5, -177.5, ..., 177.5, 178.5, 179.5])
- lat(lat)float64-89.5 -88.5 -87.5 ... 88.5 89.5
- standard_name :
- latitude
- long_name :
- latitude
- units :
- degrees_north
- axis :
- Y
- comment :
- The latitude values of the grid, in degrees, ranging between [-89.5; 89.5]. The grid is centred, i.e., a value of +0.5 corresponds to the degree [0N, 1N]
array([-89.5, -88.5, -87.5, -86.5, -85.5, -84.5, -83.5, -82.5, -81.5, -80.5, -79.5, -78.5, -77.5, -76.5, -75.5, -74.5, -73.5, -72.5, -71.5, -70.5, -69.5, -68.5, -67.5, -66.5, -65.5, -64.5, -63.5, -62.5, -61.5, -60.5, -59.5, -58.5, -57.5, -56.5, -55.5, -54.5, -53.5, -52.5, -51.5, -50.5, -49.5, -48.5, -47.5, -46.5, -45.5, -44.5, -43.5, -42.5, -41.5, -40.5, -39.5, -38.5, -37.5, -36.5, -35.5, -34.5, -33.5, -32.5, -31.5, -30.5, -29.5, -28.5, -27.5, -26.5, -25.5, -24.5, -23.5, -22.5, -21.5, -20.5, -19.5, -18.5, -17.5, -16.5, -15.5, -14.5, -13.5, -12.5, -11.5, -10.5, -9.5, -8.5, -7.5, -6.5, -5.5, -4.5, -3.5, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 10.5, 11.5, 12.5, 13.5, 14.5, 15.5, 16.5, 17.5, 18.5, 19.5, 20.5, 21.5, 22.5, 23.5, 24.5, 25.5, 26.5, 27.5, 28.5, 29.5, 30.5, 31.5, 32.5, 33.5, 34.5, 35.5, 36.5, 37.5, 38.5, 39.5, 40.5, 41.5, 42.5, 43.5, 44.5, 45.5, 46.5, 47.5, 48.5, 49.5, 50.5, 51.5, 52.5, 53.5, 54.5, 55.5, 56.5, 57.5, 58.5, 59.5, 60.5, 61.5, 62.5, 63.5, 64.5, 65.5, 66.5, 67.5, 68.5, 69.5, 70.5, 71.5, 72.5, 73.5, 74.5, 75.5, 76.5, 77.5, 78.5, 79.5, 80.5, 81.5, 82.5, 83.5, 84.5, 85.5, 86.5, 87.5, 88.5, 89.5])
Passing the last timestep#
With a basic function written we can now think about how to fix its problems. You might have noticed that in the previous function each year is calculated independently, so
API[1981-01-01] = precip[1981-01-01]
when it should in fact be
API[1981-01-01] = k * API[1980-12-31] + precip[1981-01-01]
We need some way to pass in the previous year’s api values to our function, but only if we’re not calculating the first year. We can do this with an argument that defaults to None, which looks like
def api_at_year(precip, year, previous_api = None):
If a value is not given, like api_at_year(precip, '1980') then previous_api will be None, which we can check with an if statement:
if previous_api is None:
# First year
api_year[0,:,:] = precip_year[0,:,:]
If we do pass a previous_api value, like api_at_year(precip, '1981', api_1980), then we follow the else branch to use the correct formula:
else:
# Following years
api_year[0,:,:] = k * previous_api[-1,:,:] + precip_year[0,:,:]
def api_at_year(precip, year, previous_api = None):
"""
Returns the API measure for a given year
"""
precip_year = precip.sel(time=year).load()
api_year = numpy.zeros_like(precip_year)
if previous_api is None:
# First year
api_year[0,:,:] = precip_year[0,:,:]
else:
# Following years
api_year[0,:,:] = k * previous_api[-1,:,:] + precip_year[0,:,:]
for i in range(1, precip_year.sizes['time']):
api_year[i,:,:] = k * api_year[i - 1,:,:] + precip_year[i,:,:]
api_year = xarray.DataArray(api_year, name='api', coords=precip_year.coords)
return api_year
Now we can call the function multiple times for each year. We could store each year’s values in its own variable, like
api_1980 = api_at_year(precip, '1980')
api_1981 = api_at_year(precip, '1981', previous_api = api_1980)
but these variables will then stick around and fill up memory. It’s better to save the values to file as we go, re-using the variable name:
api = api_at_year(precip, '1980')
api.to_netcdf('/local/w35/saw562/tmp/frogs_era5_api_1980.nc')
api = api_at_year(precip, '1981', previous_api = api)
api.to_netcdf('/local/w35/saw562/tmp/frogs_era5_api_1981.nc')
api = api_at_year(precip, '1982', previous_api = api)
api.to_netcdf('/local/w35/saw562/tmp/frogs_era5_api_1982.nc')
Note
Remember that everything on the right side of an assignment = gets evaluated before the variable is assigned, so in
api = api_at_year(precip, '1981', previous_api = api)
the api on the right side refers to the value from the previous assignment, so the 1980 values
There’s obvious repetition here, so we may as well convert it to a loop rather than writing the same two lines multiple times. I’ve set api to None explicitly so that 1980 looks the same as the rest of the years, it will still take the if previous_api is None branch of the if statement
api = None
for year in range(1980, 1990):
print(year)
api = api_at_year(precip, str(year), previous_api = api)
api.to_netcdf(f'/local/w35/saw562/tmp/frogs_era5_api_{year}.nc')
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
Check that the files were properly created as expected - you may also want to try plotting some of the values in these files
! ls /local/w35/saw562/tmp/frogs_era5_api_*.nc
/local/w35/saw562/tmp/frogs_era5_api_1980.nc
/local/w35/saw562/tmp/frogs_era5_api_1981.nc
/local/w35/saw562/tmp/frogs_era5_api_1982.nc
/local/w35/saw562/tmp/frogs_era5_api_1983.nc
/local/w35/saw562/tmp/frogs_era5_api_1984.nc
/local/w35/saw562/tmp/frogs_era5_api_1985.nc
/local/w35/saw562/tmp/frogs_era5_api_1986.nc
/local/w35/saw562/tmp/frogs_era5_api_1987.nc
/local/w35/saw562/tmp/frogs_era5_api_1988.nc
/local/w35/saw562/tmp/frogs_era5_api_1989.nc
/local/w35/saw562/tmp/frogs_era5_api_full.nc
Pure Dask (Advanced)#
What we’ve done so far works well as long as a year’s worth of data fits into memory. If it doesn’t you can always split the data more finely, say by splitting the data by month instead of year.
Another way to go about it is to use the Dask chunks as the mechanism to split the data. The basic idea is very similar to what we’ve already done, we just need to learn how to do the loop over dask chunks instead of years.
Dask provides the dask.array.map_blocks() function that allows you to run a function on every chunk of an array. We do lose all of the Xarray metadata when we use this, we can only use basic numpy array functions. Here’s the stripped down function we’ll use with map_blocks:
def api_block(block, prev):
"""
Returns the API measure for a dask chunk
Args:
block: a 3d numpy array with precip values,
time should be the first dimension
prev: a 2d numpy array with the api value
immediately preceding the first time in
block, or None if this is the first time
step
"""
api = numpy.zeros_like(block)
if prev is None:
api[0,:,:] = block[0,:,:]
else:
api[0,:,:] = k * prev + block[0,:,:]
for i in range(1, block.shape[0]):
api[i,:,:] = k * api[i - 1,:,:] + block[i,:,:]
return api
map_blocks runs the function on each chunk independently, which is fine if the data is chunked horizontally but if the chunking is over time then we need some way of passing in the previous time’s API value.
Let’s re-open the original dataset, adding some horizontal chunking this time, and see how we can deal with the previous timesteps. data will give you the Dask array from an Xarray object
ds = xarray.open_mfdataset('/g/data/ua8/Precipitation/FROGs/1DD_V1/ERA5/*.nc', chunks={'lat': 90, 'lon': 90})
precip = ds.rain
precip.data
|
Once we have a Dask array, dask.array.Array.blocks lets us access the individual chunks. We can index .blocks as if it were a numpy array
precip.data.blocks[4,1,3]
|
We can also iterate over .blocks, which will iterate over the first dimension, giving all the lat and lon chunks for that time chunk
for block in precip.data.blocks:
display(block)
break
|
This loop now works like the loop over years that we had before. For each group of lat and lon chunks at a time chunk, use map_blocks to compute the API for those chunks. Save the final timestep from those chunks to pass in as the previous values for the next group. Once all of the groups have been processed concatenate them back together into a single array.
api_blocks = []
prev = None
for block in precip.data.blocks:
api = dask.array.map_blocks(api_block, block, prev, meta=numpy.array((), dtype=block.dtype))
prev = api[-1,:,:]
api_blocks.append(api)
api_dask = dask.array.concatenate(api_blocks, axis=0)
api_dask
|
Finally convert the Dask array to Xarray and save to a file
%%time
api = xarray.DataArray(api_dask, name='api', coords=precip.coords)
api.to_netcdf('/local/w35/saw562/tmp/frogs_era5_api_full.nc')
api
CPU times: user 13.2 s, sys: 3.12 s, total: 16.3 s
Wall time: 2min
<xarray.DataArray 'api' (time: 15341, lat: 180, lon: 360)> dask.array<chunksize=(365, 90, 90), meta=np.ndarray> Coordinates: * time (time) datetime64[ns] 1979-01-01T13:30:00 ... 2020-12-31 * lon (lon) float64 -179.5 -178.5 -177.5 -176.5 ... 177.5 178.5 179.5 * lat (lat) float64 -89.5 -88.5 -87.5 -86.5 -85.5 ... 86.5 87.5 88.5 89.5
- time: 15341
- lat: 180
- lon: 360
- dask.array<chunksize=(365, 90, 90), meta=np.ndarray>
Array Chunk Bytes 3.70 GiB 11.31 MiB Shape (15341, 180, 360) (366, 90, 90) Count 2050 Tasks 336 Chunks Type float32 numpy.ndarray - time(time)datetime64[ns]1979-01-01T13:30:00 ... 2020-12-31
- standard_name :
- time
- long_name :
- time
- axis :
- T
- comment :
- The time values of the grid, following the standard CF calendar, in days, centred, since 1970-01-01 00:00:00
array(['1979-01-01T13:30:00.000000000', '1979-01-02T12:00:00.000000000', '1979-01-03T12:00:00.000000000', ..., '2020-12-29T00:00:00.000000000', '2020-12-30T00:00:00.000000000', '2020-12-31T00:00:00.000000000'], dtype='datetime64[ns]') - lon(lon)float64-179.5 -178.5 ... 178.5 179.5
- standard_name :
- longitude
- long_name :
- longitude
- units :
- degrees_east
- axis :
- X
- comment :
- The longitude values of the grid, in degrees, ranging between [-179.5; 179.5]. The grid is centred, i.e., a value of +0.5 corresponds to the degree [0W, 1W]
array([-179.5, -178.5, -177.5, ..., 177.5, 178.5, 179.5])
- lat(lat)float64-89.5 -88.5 -87.5 ... 88.5 89.5
- standard_name :
- latitude
- long_name :
- latitude
- units :
- degrees_north
- axis :
- Y
- comment :
- The latitude values of the grid, in degrees, ranging between [-89.5; 89.5]. The grid is centred, i.e., a value of +0.5 corresponds to the degree [0N, 1N]
array([-89.5, -88.5, -87.5, -86.5, -85.5, -84.5, -83.5, -82.5, -81.5, -80.5, -79.5, -78.5, -77.5, -76.5, -75.5, -74.5, -73.5, -72.5, -71.5, -70.5, -69.5, -68.5, -67.5, -66.5, -65.5, -64.5, -63.5, -62.5, -61.5, -60.5, -59.5, -58.5, -57.5, -56.5, -55.5, -54.5, -53.5, -52.5, -51.5, -50.5, -49.5, -48.5, -47.5, -46.5, -45.5, -44.5, -43.5, -42.5, -41.5, -40.5, -39.5, -38.5, -37.5, -36.5, -35.5, -34.5, -33.5, -32.5, -31.5, -30.5, -29.5, -28.5, -27.5, -26.5, -25.5, -24.5, -23.5, -22.5, -21.5, -20.5, -19.5, -18.5, -17.5, -16.5, -15.5, -14.5, -13.5, -12.5, -11.5, -10.5, -9.5, -8.5, -7.5, -6.5, -5.5, -4.5, -3.5, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 10.5, 11.5, 12.5, 13.5, 14.5, 15.5, 16.5, 17.5, 18.5, 19.5, 20.5, 21.5, 22.5, 23.5, 24.5, 25.5, 26.5, 27.5, 28.5, 29.5, 30.5, 31.5, 32.5, 33.5, 34.5, 35.5, 36.5, 37.5, 38.5, 39.5, 40.5, 41.5, 42.5, 43.5, 44.5, 45.5, 46.5, 47.5, 48.5, 49.5, 50.5, 51.5, 52.5, 53.5, 54.5, 55.5, 56.5, 57.5, 58.5, 59.5, 60.5, 61.5, 62.5, 63.5, 64.5, 65.5, 66.5, 67.5, 68.5, 69.5, 70.5, 71.5, 72.5, 73.5, 74.5, 75.5, 76.5, 77.5, 78.5, 79.5, 80.5, 81.5, 82.5, 83.5, 84.5, 85.5, 86.5, 87.5, 88.5, 89.5])
As a check, make sure the values from the chunked calculation match the very first 1D calculation
api = xarray.open_dataset('/local/w35/saw562/tmp/frogs_era5_api_full.nc')
numpy.testing.assert_almost_equal(api.api.sel(lat=-37.81, lon=144.96, method='nearest').values, api_mel, decimal=4)
Conclusions#
There are a few points to keep in mind here:
In the majority of cases it’s better to operate on the whole horizontal grid, rather than one grid point at a time
Build up your analysis in stages - here we first computed a single year, then changed that into a function, then updated the function to deal with the successive years
Check often to make sure your results are sensible, e.g. by plotting values
We’ve focussed more on memory use than speed here, if improved speed is desired you could look at functions like scipy.signal.lfilter() or using numba instead of the loop over timesteps.